Showcasing hackathon projects
Whenever a new Engineering Partner (EP) is onboarded at Commit, they get their feet wet by doing a Hackathon Onboarding Project (HOP). This involves building a project of their choice, then open-sourcing and sharing what they’ve learnt and demoing the project. Quite often the HOP demos are run on the EP’s local machine, for various reasons: cost of hosting, complexity of infrastructure, lack of experience with DevOps, and to make it easier for the EP to spend more time on the project. At Commit we’re always keenly focused on enhancing the Engineer experience, so we’re motivated to offer EPs an easier and better way to showcase their projects and learnings. Thus my own hackathon project was born: to build a deployment platform for EPs.
Reducing the learning curve of DevOps
The goal of this project is to help new EPs deploy their Hackathon Onboarding Project with ease, and have their projects deployed on a shared Kubernetes cluster. We all know that getting a project up and running in AWS and deployed on Kubernetes can be a project of its own, and we don’t want this to take away from EPs’ hackathon projects. So we had to build a solution that allows for a wide variety of backend and frontend projects to be easily deployed on our infrastructure. Our goal is to stay as close to a real-world scenario as possible and allow EPs to clone a repo and quickly deploy with minimal setup and effort to avoid the steep learning curve of many DevOps tools.
Leveraging open source of our own
What about Zero, you may ask? Zero is an open source tool developed internally at Commit that can scaffold, customize and provision a production-ready infrastructure following best practices and an application boilerplate for SaaS startups to quickly get up and running. In this case we’re using the infrastructure only. Zero sets up all the infrastructure essentials and tools, then provides us with infrastructure as code using Terraform. This allows us to easily provision our entire infrastructure in a predictable and repeatable way. Since we are building a deployment platform as a demo environment rather than a traditional SaaS application, we would have to share the cluster resources and deployment flow across projects and make some changes to the infrastructure. There were a few challenges, tweaks and many learnings in between to make this work. Let’s dive into the details!
Abstracting away the deployment complexity across projects
For backend services, we wanted to deploy seamlessly via our continuous delivery pipeline like we would in a normal development workflow. Traditionally we would have the access control set up so each project only pushes to its own Elastic Container Registry (ECR), but in our scenario we wanted to avoid having to make a new ECR repository on AWS for each project. That would mean we have to grant permission to our continuous integration (CI) user to access each new ECR repository. We opted to share the repository and namespace the images instead. Using Github’s organization secrets, this allows repositories across the Github organization to share credentials and secrets, therefore each individual project’s CI pipeline can reference and deploy to a common ECR repository using the Github expression syntax in Github Actions.This allowed us to set up many projects while sharing the credentials and eliminating the need for per project maintenance on the infrastructure, by using a common org-level set of parameters across repositories, making this both maintainable and dynamic. If something had to be changed across all repositories, we can simply edit the org-level secret and it will take effect for all the repositories. To differentiate the docker images across projects, instead of just tagging with git hash we also prefixed it with the repository name. Given that the goal was to demo hackathon projects, we were not too concerned about sharing the ECR repo within our organization.
Simplifying the Kubernetes ops
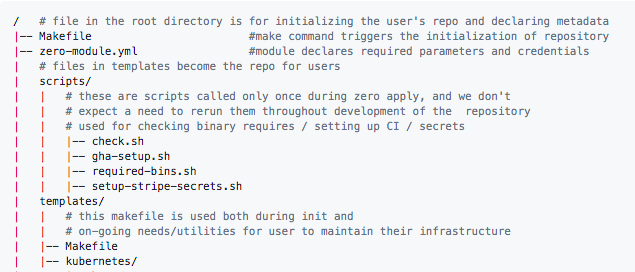
Zero’s backend service template was the best starting place for this, as it ships with a CI/CD pipeline that builds, pushes and deploys backend services. For Engineers’ hackathon purposes we didn’t need the stage, production or authentication concepts, or the SaaS application boilerplate, so I gutted most of the environment and application logic to make it more generic. In order to let EPs deploy their hackathon projects on our common Kubernetes cluster without taking much time away from the actual content of the project, this meant that we had to make some assumptions and abstractions to simplify the workflow while trying not to deviate from a normal development flow. To allow each project to have its own sandbox-like experience, we can simply create all the project’s resources in a single namespace.
This also means the cleanup will be simple, as we can simply tear down the namespace. The backend project template ships with Kuberentes manifests that contain an ingress, service and deployment, so it is readily discoverable once deployed. These are all prepared and organized into a folder and applied using Kustomize during the CI pipeline. Zero ships with cert-manager and ExternalDNS in the cluster, so any ingress with the correct annotation will be automatically set up with an https certificate. A route53 entry will also be created automatically to point traffic at it. Since we are not hosting any production workloads, we are using spot instances to cut down the cost significantly, which Zero lets us configure out of the box.
Templating out a deployable boilerplate
Since a boilerplate project only contains static content, but we need to dynamically give each project a different namespace and customize the Kubernetes manifests to not have conflicts deploying into a shared cluster, we had to find a way to dynamically generate the manifest. Making things easy to use, and helping EPs get started quickly, meant minimizing the need for learning new tools and specific workflows to template out the deployment configuration. We explored the idea of setting up a Github template repository for engineers to clone their boilerplate in a few clicks. Templating out a repository using a Github template is still only static content, meaning engineers would have to understand and configure all the Kubernetes manifest and CI/CD pipeline configurations, or they would have to download a templating tool and generate it themselves locally, then commit the templated content back to the repository.
During this process I came across this article by Stefan using Github templates, Github Actions and cookiecutter to scaffold and template out a repo at the same time. This was perfect for our scenario, except for one thing: cookiecutter doesn’t allow customizing the delimiter, and it conflicts with Github Actions’ expression syntax. With cookiecutter’s mustache syntax {{ cookiecutter.<PARAM> }} and Github Actions’ expression syntax ${{ github.repository_name }} it will try to template out the Github Actions content, since it’s the same delimiter, unless we add extra logic to escape the {{}} which would make the original code less readable. Also, why bother with another templating tool when we already have Zero? We already use it to scaffold the infrastructure and the binary is publicly available, so we just download the Zero binary in Github Actions and use it to template the content. With this method we were able to template out the content containing Github expression syntax and use other Zero templating features , then use the same workflow to reinitialize the repo with Github Actions.

The “setup and reinitialize” workflow templates out then rewrites the git history of the repository. At this point your repository will contain the newly created content and kick off the application deployment pipeline. We also included a simple helloworld endpoint in the backend example, so at the end of the deployment your backend should be live and available to curl.

All that’s required from the user is editing the service name and committing the change through the web UI. EPs will get a repository with a working CI/CD pipeline that is already deployed to the Kubernetes cluster with their own namespace and deployed application.
Accessing the cluster
For EPs to check on their deployment logs and troubleshoot they may need access to the cluster. To accomplish this we connected our Google Workspace as an identity provider for AWS Single Sign-on, and a role that allows access to the Kubernetes cluster. Because all EPs have a Commit Gmail account, they can simply use that same account to log in to our AWS account without an explicit AWS user being created. With a script included in the backend service template, they’re able to simply run a command that will open their web browser, prompt them to log in or select their Commit Gmail account, and configure their local CLI tools, giving them immediate access to the things they need.
Serving static frontends
Our static sites are all served from AWS’ CloudFront CDN with the content stored in S3. It sounded easy initially but actually turned out to be quite tricky. We wanted to make sure we didn’t need any AWS configuration changes on a per-project basis, so we wanted to avoid the process of setting up CloudFront configurations, origin access identities and bucket policies, so we can have a maintenance-free setup. Therefore we would need to dynamically serve each different project’s content from the same S3 bucket. We opted to use S3 prefixes (directories) and store each project’s static content in the same bucket but separate subdirectories. This setup is elegant because S3 allows us to sync a local directory to a prefix during deployment, meaning we can share the exact same code for deploying all frontends in the CI pipeline. But we wanted to make sure we exposed a simple URL, for ease of use. For example, my-project.domain.com/ instead of domain.com/my-project/index.html. To solve this we set up a CloudFront behaviour with lambda@edge on the viewer’s request. CloudFront behaviours allow us to hook into one of four events: viewer request, origin request, viewer response and origin response.

The one we are modifying is the viewer’s request — at this event it determines the origin URL and fetches it from the origin (S3). We set up a wildcard route53 entry and CloudFront alias so that all subdomains point to CloudFront distribution (e.g., project1.domain.com). The request header hitting CloudFront will have the host value and we can use a lambda function to modify the request URI so it uses the subdomain in the path, dynamically modifying the request destination.

With the setup above I was able to dynamically serve frontends at the root of each subdomain and have the relative paths working. :yay: But then I realized all the other pages give me an “S3 key does not exist” error, because for serving single-page apps, we were relying on an error behaviour set on Cloudfront to serve index.html whenever the destination file did not exist in S3, and this error behaviour is what allows something like React router to reference paths that don’t actually have content to load from the server. I ended up with a workaround solution that has some limitations but works, for the most part. I ended up parsing the tail part of each URL to determine whether the path points at a file or not with a regex like /\/([\w-_\.]+\.\w+)$/.
If it doesn’t look like a file, we consider it to be an SPA route and load index.html, otherwise it’s assumed to be a file (e.g., images, assets or javascript) and the file is loaded from S3 and served to the browser. This is not a perfect solution as it does not look at whether the file exists or mime-types, so it can misinterpret file paths as routes if they don’t have an extension.
What about static sites that aren’t single-page apps?
Traditional static websites or hybrid frontend websites (e.g., Next.js) work a little differently than single-page apps. Their URLs resolve to actual html files. This means we don’t need the SPA behaviour of differentiating between routes and files. I ended up setting up another subdomain (project2.static.domain.com) and using the subdomain .static or .spa to determine how content will be loaded. With this setup I was able to serve both types of frontend web applications from the same S3 bucket, but on different domains.
A more robust solution?
In a web server such as Apache, a common solution is to use .htaccess rewrite rules to check whether the files exist before loading index.html. We could potentially do the same by having the lambda function fetch from S3 to see if this content exists to make the determination, instead of the fragile regex to determine whether it’s a file. I’m definitely all ears if you have a more elegant solution to accomplish this!
Tada!
With this approach we are able to set up a simple workflow: with just a few clicks on the Github interface, you have your own repository and application deployed on the cluster as your starting point. Then you can commit your changes to this repo and it will automatically deploy them, so people can check out what you’re building. We think this is an easy and efficient way for Commit EPs to get their apps and HOPs into other peoples’ hands, provide a better demo experience, and expose Engineers to some of the great tooling built into the Zero ecosystem.
David Cheung is a staff software engineer at Commit. He has been honing his expertise in full-stack software development for over a decade and is passionate about open source projects.
###