As part of the testing for our open source project Zero, which helps early-stage startups accelerate the development of their product, we are constantly trying to improve the infrastructure and tools in the Zero ecosystem. To this end, I was trying to make a switch to using Amazon Web Services’ Network Load Balancer from their “Classic” Elastic Load Balancer. NLB is billed as AWS’s next generation of load balancers. I was hoping for a better experience than I’ve had with ELB—although my experience with ELB has been mostly positive, as it tends to be fairly fast and stable. We’ve been using ELB with Kubernetes for quite some time, so I’m confident in how these technologies work together.
The goal was to be able to use Network Load Balancer stably as the load balancer on the edge of our infrastructure, sending traffic to an internal Elastic Kubernetes Service cluster running Nginx Ingress Controller. I want to be able to add and remove nodes, do a deploy rollout to the ingress controller without any disruption of traffic, and retain client IP information for logs and application functionality.
I found that in all three modes of operation—External Traffic Policy: Local, External Traffic Policy: Cluster, and NLB–IP—there were gotchas that would lead to traffic loss under not unrealistic conditions, such as nodes being added and removed and rollouts of the ingress controller. The ingress controller is a fairly stable piece of the setup and shouldn’t require many updates, restarts, etc., but I expect to be able to perform these operations when I need to, without any impact on users.
I’m going to dive right in on some topics, so hopefully you have some knowledge of Kubernetes and AWS networking.
Components
Network Load Balancer: The piece exposed to the internet. It accepts traffic on a public IP, then sends the traffic to targets in its target groups, which can be either EC2 instances or IP addresses. In our case, these targets are all on a private VPC, inaccessible from the public internet.
Nginx Ingress Controller: Receives traffic from the NLB. It’s a pod or group of pods running in the EKS cluster that expose their IP addresses to receive traffic from hosts on the internal VPC, including the NLB, and route HTTP traffic to services in the EKS cluster based on various rules. The way traffic can get to the ingress varies depending on the configuration, which will be referenced below in the Modes section. In our testing, the ingress was sending traffic to another internal service, an echoserver pod, which received HTTP requests and printed them back in its responses. The focus of this testing is on the behaviour of the ingress and NLB though, not the backend application.
AWS Load Balancer Controller: A controller pod created by AWS that can run in the cluster and enable a special “NLB–IP” mode, which allows an ELB to register individual pods as targets using their cluster IP.
The controller can be easily installed with Helm. To use it, a LoadBalancer-type service needs to have the annotation:
service.beta.kubernetes.io/aws-load-balancer-type: "nlb-ip"Other annotations can also be added to control the settings of the NLB and targets.
One additional nicety with the controller is that it exposes the target information through a Kubernetes Custom Resource called TargetGroupBinding, which you can use to easily check the status of the target groups managed by the controller:
Modes
IP mode
This mode of operation is enabled by using the AWS Load Balancer Controller. The controller watches the endpoint IPs of a LoadBalancer-type service and makes AWS API calls to register those IPs as targets in the appropriate target group for the NLB. Since we are using the AWS CNI plugin, each pod receives its own IP address on a subnet in the private VPC, so the NLB can send traffic to the pod directly.
An example is a service like this:
In this case, you can see that the ingress service references two IPs that can receive traffic on ports 80 and 443.
The controller will register these as targets as you can see below in the NLB target group UI. In this case, there are two ingress controller pods.


In this mode, the NLB balances traffic directly to the pods, bypassing Kubernetes’ internal load balancing. This can be a tiny bit faster, as it doesn’t require an extra network hop through the worker nodes.
ExternalTrafficPolicy: Cluster
This mode of operation is a native Kubernetes mechanism enabled by setting the ExternalTrafficPolicy setting on the LoadBalancer service to Cluster. It operates by opening a certain port on all the worker nodes in the cluster, regardless of whether there’s a pod able to handle traffic for that service on that node or not. Any traffic sent to any worker on that port will be forwarded by Kubernetes to one of the pods of that service.
In this case, there is one ingress controller pod.


This mode can be very useful because it often results in less churn of targets in the cluster, since it doesn’t depend on the state of the pods in the cluster. Any request can be sent to any node, and Kubernetes will handle getting it to the right place. It results in good load-spreading from the ELB or NLB and can reduce hotspots where a small number of nodes end up receiving all the traffic. The drawback, however, is that it can result in an extra network hop since your request might hit a node that doesn’t have the right pod on it, and then need to be sent to another node. It also obscures the source IP address, as the traffic will appear to be coming from another node in the cluster. This can be mitigated by enabling Proxy protocol on the LB and in Nginx config.
Note: Proxy protocol can’t be set on an NLB currently, unless you do it manually through AWS. There is an annotation but it is only recognized by the AWS LB Controller, which only supports IP mode, which sends to a pod IP, so Cluster mode is not applicable.
ExternalTrafficPolicy: Local
This mode of operation is a native Kubernetes mechanism enabled by setting the ExternalTrafficPolicy setting on the LoadBalancer service to Local. It operates by opening a certain port on the worker nodes in the cluster, but only forwarding traffic for nodes that have the right pod running on them. This will cause the ELB/NLB health checks to fail, and traffic will not be sent to nodes that are not able to handle it.
In this case, there is one ingress controller pod.


This mode prevents the extra network hop from Cluster mode, but adds some potential for your traffic to become imbalanced. For example, if you have two pods on one node, and a single pod on the other, the NLB or ELB will send the same amount of traffic to both nodes, but on the node with two pods that traffic will be split between the pods, while on the other node all the traffic will be handled by a single pod. This will result in one pod handling double the number of requests of the other two. Since it relies on the Load Balancer’s health checks to be able to discover if a node can handle requests, it can also add some delay during a deployment of the ingress controller or some other event that causes the pods to move between nodes.
Tools
siege HTTP load tester: I used this to send constant traffic at the load balancer to watch for disruptions.
kubectlKubernetes CLI: Used to interact with the EKS cluster. I alias this to k.
sternWatch Kubernetes pod logs: This is a tool that makes it easy to watch the logs from groups of pods at once, with colourized output
awsAWS CLI: I use this to interact with the AWS infrastructure during testing. All the infrastructure was provisioned using Terraform generated by Zero.
How did the testing go?
In each section I’ll mark successful or failed tests with ❌ or ✅ where a success means I would consider it to be a good candidate for use in a production environment. Some tests show both where there are certain cases that exhibit non-ideal behaviour.
Target registration
The first issue I started running into with the NLB was the “target registration” time.
Each target in a target group has an associated state:
healthy, unhealthy, initial, drainingand a couple more.
- healthy and unhealthy refer to whether or not the target is responding correctly to its health checks. A healthy target will receive traffic, while an unhealthy one will not.
- initial means the target was recently added. The load balancer is registering the target or starting to do some initial health checks. I noticed that some traffic may actually be sent to this target before the status is changed to healthy.
- draining means the target is being removed, and is in its configurable draining period. The load balancer should not send traffic to this target, but the target has some time to finish up any requests that are currently in progress.
With an ELB, adding instances is nearly instantaneous. A new instance is added as OutOfService, performs its health checks, and switches to InService. With NLB I was seeing consistently long times spent in the initial state before a target would switch to healthy. The average time was four to five minutes. The quickest addition I saw was about three and a half and the longest was over six minutes. This is even with the minimum health check settings of two consecutive checks at a 10-second interval, which adds 20 seconds.
This causes issues with the various modes:
Ingress controller rollout
There are some cases where you may need to deploy a new version of the ingress controller which will do a rolling deployment of its pods.
During a rolling deploy, the new pod will come up, Kubernetes will run readiness checks against it, it will be marked as ready, then the old pod will be terminated. On the Kubernetes side, this behaviour is great because it makes sure that there is always a pod ready to serve traffic.
With NLB–IP mode ❌ / ✅
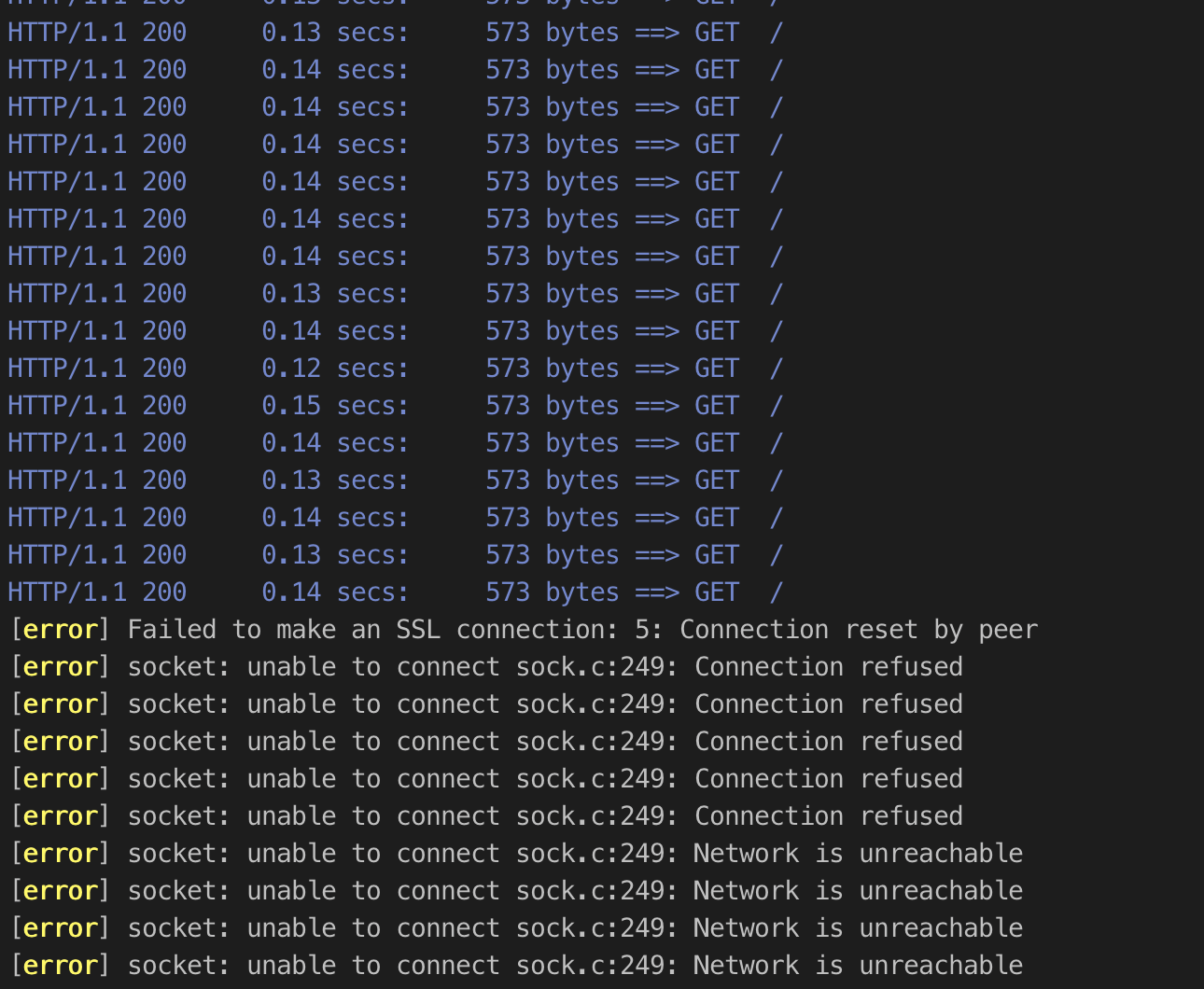
Externally it’s a bit of a different story. Since we are running in IP mode, when the new pod comes up it will register a new target which will go into its four- to five-minute initializing state. When the old pod is terminated, the NLB health checks will start failing and it will go into the draining state. During this time requests to the LB will time out because there are no available targets. This even affects deployments with multiple pods, since the whole rollout will happen before the target registration completes.
Here is what the target group UI looked like when I ran
k rollout restart deploy -n ingress-nginx ingress-nginx-controller and here’s what we saw from siege during that time:


The way around this is using pod readiness gates, a feature supported by the AWS LB controller. This makes it so that the pod will not be marked as ready in Kubernetes until the NLB finishes initializing the target, which works but also adds four to five minutes to your pod startup time. In the case of a node that’s going down because of a spot termination, you may not have that much time to move it. If you have a handful of pods it means your deployment will take quite a while to complete.
To enable pod readiness gates on the ingress controller, you just need to label the namespace like so:
k label namespace ingress-nginx elbv2.k8s.aws/pod-readiness-gate-inject=enabled
With Traffic Policy: Local ❌
In a situation with a smaller number of pods than nodes, there is a high likelihood that pods will be distributed to new nodes. This means that some of the targets will go through target draining, and some new ones will enter their initialization period. This may result in traffic loss as the NLB health checks may not mark the target as unhealthy in time to prevent requests from being sent to it.
With Traffic Policy: Cluster ✅
As long as it’s a rolling deploy there should always be at least one pod running, and there should be no loss of traffic as Kubernetes will be internally balancing traffic to a pod regardless of which node received the request from the LB.
Node stop
Occasionally a node may be stopped due to Cluster Autoscaler deciding the cluster is over-provisioned, a spot instance termination, or another reason. Typically in this case a node is cordoned to prevent new workloads from being scheduled, and drained to move any existing workloads to other nodes. In this case, the expectation is that any ingress controller pods are moved over to a new node without any loss of traffic.
With NLB–IP mode ❌
I assumed that if I had multiple pods it would be okay as long as the node was drained. The NLB should mark the old target as unhealthy and keep sending traffic to the new one, with the timing depending slightly on health check settings. When I tested it, however, I found that it doesn’t handle this case well at all and loses traffic during node shutdown. This was what happened when setting the desired instances from two to one with one ingress pod on each node:

As expected, the old target moves to the draining state and the new one comes up in its four- to five-minute “initial” phase. In this situation, I would expect that all is fine because there’s still a healthy target.
However, I noticed some odd behaviour in this case. As soon as the target moves from healthy to draining (and sometimes near the end of the draining period) I would see intermittent connections hanging. It seems like somehow when the target is draining it still sometimes receives traffic. For example, if there was one healthy target and one draining, when this was happening I would see about half of my connections hang.

With Traffic Policy: Local ❌
With this configuration, I saw the same as above. When a target switches to draining I would see connections hang.
In the case of removing a target that was not serving traffic, this behaviour did not occur. For example, removing a node without an ingress controller on it. In this case, the target would go from “unhealthy” to being removed, without a “draining” step.
I also saw some cases where a target would go from healthy to draining to removed within a couple of seconds, and this would also result in hung connections.
See this example where I am polling the status of targets in a group after lowering the desired instances from two to one:
while true; do date && aws elbv2 describe-target-health --target-group-arn "<arn>" --query "TargetHealthDescriptions[].TargetHealth.State" && sleep 1; done
With Traffic Policy: Cluster ❌
I saw the same weird behaviour where I got timeouts as the target was draining. Even when draining a node that didn’t have any pods on it, presumably because it’s still trying to send requests to both nodes due to Cluster Traffic Policy.
Node start
When scaling out the cluster or replacing a node that was terminated, a new node will come up and join the cluster. It may have workloads scheduled to it, and when that happens the expectation is that there should be no disruption.
With NLB–IP mode ✅
Most likely this will be fine. If pods are rescheduled to the new node(s), they operate as independent targets per-IP, so the Pod Readiness Gate should slow the deployment to make sure each target is ready before terminating the old pods.
With Traffic Policy: Local ❌
It’s a bit unlikely, but if new nodes were started and then ingress pods were rescheduled to the new nodes within the four-minute startup time there would be a loss in traffic. Using Pod Readiness Gates could be an option here but it’s not supported by the AWS LB Controller unless you are running in NLB–IP mode.
With Traffic Policy: Cluster ✅
Even in the case where nodes are started and all workloads are rescheduled to the new ones, Kubernetes should distribute the traffic properly.
New nodes do take a while to serve traffic though due to the four-minute target registration.
ELB for comparison
Rollout with Traffic Policy: Local ❌ / ✅
You are at the mercy of the health checks defined for the LB. If you do a rollout and all pods are scheduled to nodes that didn’t have pods on them before, all your requests will hang until the health checks fail against the old nodes and succeed against the new ones. Since there’s not a pod readiness gate, kubernetes has no concept of the readiness of the ELB, so the deployment will fully roll out because the pods are marked as ready without the ELB instances necessarily being ready. This will happen in the case where you have at least twice as many nodes as ingress controller pods.
Rollout with Traffic Policy: Cluster ✅
No loss of traffic, same as NLB, but additionally Proxy Protocol works properly. During a deployment, even if all ingress pods are moved to new nodes, the internal Kubernetes load balancing will send the requests to the right nodes.
The downside is an extra network hop, which is unlikely to add any more than a millisecond per request which is probably not an issue for many smaller-scale systems.
Node Stop: Cluster ✅
If there is just a single ingress pod—hopefully not the case on a production system—traffic will be lost if the node containing that pod is stopped, as you are at the whim of ELB health checks.
If there are multiple pods, you may have a couple requests that take longer as they are retried internally right as one pod is removed, but nothing should be lost—assuming the pods are balanced properly across nodes as a daemonset or with anti-affinity.
Summary
While I liked the idea of NLB and was looking forward to trying it out, I had to switch back to using ELB due to the various issues I found. The four- to five-minute registration period for new targets was quite frustrating and the random connection timeouts during target draining shook my confidence in it.
There are some things I do like about it. The idea of being able to use IP mode to register individual pods as targets is very cool, and being able to query the target info through Kubernetes using the TargetGroupBinding custom resource is a great idea.
We have switched back to using ELB for now, but I’ve asked AWS about the issues I had, and if I hear back I’ll certainly update this post, and hopefully there are some resolutions to these things so I can try switching over again sometime in the future.
If you have any questions, comments, corrections, or suggestions, feel free to comment or contact me at bill@commit.dev
Additional Notes
Trying to change an existing service between ExternalTrafficPolicy Local and Cluster on an NLB will cause problems. Kubernetes will be unable to edit the targets and if you describe the service you’ll see this message:
Error syncing load balancer: failed to ensure load balancer: error modifying target group health check: "InvalidConfigurationRequest: You cannot change the health check protocol for a target group with the TCP protocol..." (Instead of the always reassuring message “Ensured load balancer”)
The AWS LB Controller ONLY supports NLB in IP mode and ALB, not NLB in instance mode. This means some of the additional annotations and functionality you get from the controller will not be available unless you use IP mode.
NLB: When a new node is added, the target is only created in the initial state when the node transitions from NotReady to Ready in kubectl’s output.
NLB: When a target is transitioning to a healthy state, traffic seems to start flowing to the node about 15 seconds before the target changes state from initial to healthy.
ELB: When a node transitions from healthy to “SchedulingDisabled” (cordoned), the instance is immediately removed from the LB – within about a second.
ExternalTrafficPolicy Cluster vs Local makes no difference with NLB-IP mode. In this case, the NLB isn’t sending traffic to the NodePort port since it’s going directly to the pod IP. The aws-lb-controller uses the endpoints of the service to create and update NLB targets in its target group. Probably why it shows Port as “1” in the AWS UI, which is a bit weird.
Testing configs and commands
Watch NLB targets
while true; do date && aws elbv2 describe-target-health --target-group-arn "<arn>" --query "TargetHealthDescriptions[].TargetHealth.State" && sleep 1; doneWatch ELB instances
while true; do date && aws elb describe-instance-health --load-balancer-name <name> --query "InstanceStates[].State" && sleep 1; doneWatch nodes and ingress pods
while true; do date && k get node && kp -n ingress-nginx -o wide && sleep 1; doneSend traffic to service (relatively light—two concurrent connections)
siege --no-follow -c 2 -r 1000 https://echo.zero-bill.onlineConfiguration: https://gist.github.com/bmonkman/b074d633275c49380ebe7f0d89e28f1c
We hire Software Engineers to build their careers with promising early-stage startups. Join the waitlist today!
Bill Monkman is Commit’s Chief Architect.