Looking at an efficient and effective way to stream data out of a monolithic code base and into a services-based architecture.

source: macrovector
Introduction
What problem are we trying to solve?
As a monolithic code base builds up over time, it can become harder and harder to maintain, and more difficult to extract data from, especially if it was built in a legacy language that isn’t commonly used or known.
Many organizations with legacy monolithic code bases face a challenge in scaling their data. Some use tricks such as manual database sharding to segment their data, but approaches like this can make the data and corresponding code hard to maintain and overly complex. The result? Poor productivity when working with the monolith, which in turn slows down feature development.
A further complication is that many databases have consistency and structure issues, such as duplicate columns, foreign keys that are not marked as such, and poorly named or unused fields. To extract usable data efficiently, we need the database to be clean and tidy.
What’s the ideal outcome?
The ideal is to be able to pull out data and segment it easily and logically within services that are accessed via an API, so it can be maintained by separate teams who own a relevant portion of the data, related to different business needs, perhaps. As you isolate services, you can reduce the risk of bringing down the entire platform with a bad deploy.
The process of extracting usable data from your monolith should be efficient, repeatable, friction-less and fault-tolerant. It should also be scale-able, so that it doesn’t break down or become unmanageable when the business, product or team grows.
So how do we do it?
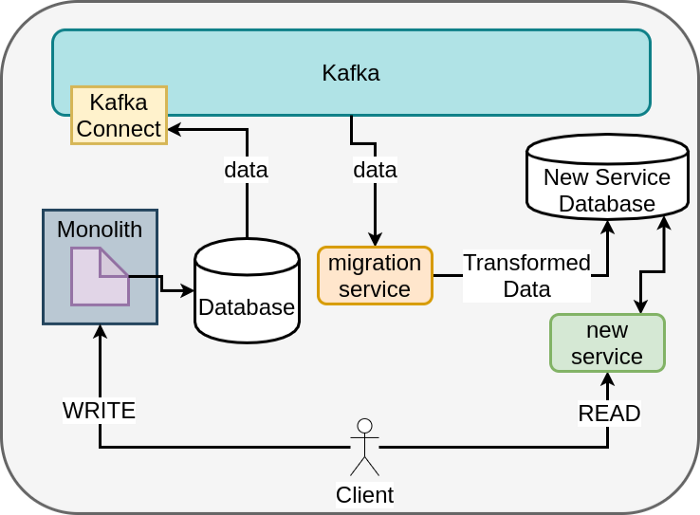
One way is to use CDC and Kafka Connect.
CDC (change data capture) is a methodology for capturing the changes that affect data within a data source. For example, you can capture the database operations INSERT, UPDATE or DELETE as well as the effect that operation has on the data in your database at the time of capture.
You’re probably familiar with Kafka. It’s a scale-able, distributed, durable and fault-tolerant streaming platform — a publish-subscribe messaging system used to transport data from one system to another. Kafka can be used for many tasks, so even though you’re setting it up for service and data extraction in this case, it can be reused as infrastructure for other processes that require data from your business. For example, you could use it to set up ETL pipelines or drive data to business intelligence systems.
Kafka Connect is a technology that allows you to connect and ingest data from various sources into Kafka, so we can use it for our CDC implementation. Here are the steps to stream out data from your monolith and into manageable services.
1. Choose your service
For your first service extraction, pick a service that’s easy to work with. A single business domain, for example. You want a subset of data with a single point of interaction between the code and the storage. The more points of access to the data, the more complicated it will be to point the monolith to the new services. If you can consolidate access to the data, you can point to the service you’re pulling from your monolith in a single place, instead of in multiple places, which ends up increasing complexity and can be very error prone.

Choose a service with a stable data model, clients and API. If they aren’t changing frequently, we can focus on a finite set of data instead of having to deal with changes, which can lead to complications in the data migration stage.
2. Create a new data model
When you pull out a service, you’ll have to pull out data and form a model or schema to store the data in. Do not simply take the old schema and replicate it in the service. Over the life of the monolith, it’s very likely that your schema has been modified many times, and not always in a productive way. Create a new data model that works for your current reality.
To do this, analyze the old schema:
-
Is it fit for its purpose?
-
Is it missing foreign keys or other good database practices? Are all the types accurate for the values you’re trying to represent?
-
Are the names of the columns relevant? Are they neutral? If a new person joined your organization, how long would it take them to understand what each column represented?
-
Is all the data being used? Will it be for the foreseeable future?
Based on your analysis, create a new schema.
3. Setup the data migration infrastructure
Now that you know what service you want to pull out and what you want the data to look like, you need to deal with the existing data maintained by the monolith. A good option would be to use CDC to snapshot existing data and keep any changes in sync with the new database you are building out. This can be achieved using Kafka Connect. Kafka Connect provides a mechanism to ingest all the data in the monolith database, along with any changes that happen to the data, via messages in Kafka.

Once the infrastructure is set up, we’ll build a migration service that will ingest the messages provided by Kafka Connect, transform them into something that matches the new schema we created for the service, and persist them to the new database.
4. Build out the service skeleton
One of the first steps is to build out your CRUD layers for your data entities. This will help structure a basic architecture to use within the service. Add essential components here such as authentication — elements that will have a significant impact on access to the data. You should finish this stage with a set of basic API tests and unit tests. This will start building the base of your test suite. It would be best to implement a CI/CD pipeline here, which will ease collaboration for the next stage, and ensure that every commit to the code base runs against a set of tests.
5. Re-implement the features
Now that we have the basics in place, we can start looking at the business logic of the service. Just as in the data modeling step, be cautious when pulling features. Ask yourself if the feature is being used today, or if there is a better way to achieve the same result. It’s useful to get a member of your Product team or someone in tune with how your system works to really understand what users want. A point to note here is that if you do change or remove functionality, remember that your existing clients have to deal with the change. So you need to weigh the trade offs to determine if a particular change is worth it.
As you build out these feature endpoints, think about what can be generalized to help minimize the amount of work required. Most importantly, avoid straight copying and pasting logic. Evaluate the old code and see if it’s optimal and meets best practices. If you have existing API tests, they would be useful to help compare the behavior of the old system to the system you are building.
6. Get production-ready and get retrospective
Set up alerts on error logs, key metrics such as restarts, and response times. Conduct a logging audit to make sure that no sensitive information is being logged, and that errors are being logged and at the right level. Run a retrospective on everything you’ve done up to now. This will help streamline the process (which gets repeated as you break down the monolith into separate services) and resolve potential issues for the next time you pull out a service with its data.
7. Roll out
It’s time to migrate. Migrate the READ side first, as this allows you to change clients independently and keeps the data in the monolith while it’s being replicated in the new format to the service.

Once all clients are updated to use the new service for READ, switch over to the WRITE portion. To help with this stage you can use feature flags to isolate particular clients, which will allow them to use the new service you built selectively. A feature flag is a technique that adds the ability to turn features of your application on or off based on a criteria you set. LaunchDarkly is an example of a platform that could help out with this.
After moving to the WRITE stage, it will be hard to transition back, unless your migration service has a bi-directional sync, but in most cases this isn’t worth the time or complexity. When all the clients have had READ and WRITE swapped over, all new data will only be in the service.

At this point you can start removing the legacy back end code, and look at repeating this exact process with another part of your monolith.
Thank you to Pritesh Patel for writing this article.