This article was written by David Cheung.
Leveling up our docs
We’ve been heads down working on Zero for the past while, but as the scope expands and features get more complex, we are at the point where markdown files in GitHub need to be organized better for ease of readability and discovery. So we’ve built a documentation website!
Requirements for the documentation site
Code should live with its docs
Documentation is part of the software—if users can’t figure out how to use the software, then there is no value delivered. If the docs aren’t in the same repo as the code, people will invariably forget to update them, and if the docs are out of sync with the code, they are almost useless.
For an open source project, if a community member is generous enough to share their improvement back to our project, we want to make documenting their work as hassle-free as possible. If contributors had to clone an entirely different project just to document their work, it becomes twice as hard.
Low maintenance
We don’t want documentation to be the reason someone didn’t contribute to our project, so it has to be easy. All our existing documentation is already written in markdown—we think it’s the best format because even pre-rendered it’s designed to be highly legible, making it easy to consume and easy to edit.
Nice to haves
In this cut-throat world where everything is ROI, we also want to pick the tool that offers the most benefit for our effort, so we have to be as greedy as possible. What we’re looking for in a tool:
- Highly customizable and extensible, so we can control the look and feel
- A large user base for ease of learning and support
- A proven success, with large, complex projects using it
- A modern stack, so it doesn’t become obsolete quickly
- Feature rich, so we don’t have to build many common things everyone needs
- Easy to deploy, so it can easily live with our code
Docusarus 
You may think the cute green dinosaur drew us to Docusaurus, but let’s not be so shallow. Let’s see how this green dinosaur checks all the boxes, and in many cases surpasses our expectations for how easy it is to add certain features (see feature rich below).
Docs living with the codebase:
The doc site can be completely isolated in a folder in the root of the project.
Low maintenance:
With the Docusaurus 2.0 beta, generating the navigation is easier than ever, you can simply specify the folder where the documents are. The setup also allows fine-grained control of the sidebar order and display with a couple lines of metadata and it will do the rest.


It also supports both md and mdx files, and will scan the folders and discover all your new documentation “automagically” as you add new documents.

High customizable and extensible:
The project is theme based, and you can go as far as extending a specific component in a theme. This feature from Docusaurus is called “swizzle.” You can simply run
npm run swizzle <theme name> [component name]
It will make a copy of your component and you can make any changes you want. This makes all themes basically infinitely customizable, and these components are all written in React.js, so it’s already familiar to many.
Large user base with support and proven success:
It was created by Facebook and many projects with millions of users are using it, such as Jest, Redis Labs, React Native, Create React App and many more.
Modern stack:
Docusaurus is a documentation framework built using React.js that can organize and render your documentation written in markdown. It is also modular by design. It’s simple and familiar to most folks who have worked with any create-react-app. There are similar concepts like `dev / export / serve` that most modern frontend stacks share.
Feature Rich:
This is definitely one of the most impressive things about Docusaurus. There are many features: auto-generated sidebar navigation, dark/light theme automatically included with an easy switcher, versioned docs can be generated with one command, Google Analytics is built in and enabled simply by putting the tracking identifier in the config, simple API key plug and play with Algolia search, supports markdown and MDX, which allows React components to be in your markdown files, and the plugin system makes all these extensible.
Smooth sailing from here, right?
Not exactly. For Zero we have multiple repositories, so how can we have code “live with its docs” without having multiple websites? In our core offering we have five modules so far: Zero CLI, infrastructure module, go-backend module, node-backend module, and a React frontend module with the Zero CLI as the main entry point.
One potential option would be a single build pipeline where at build time we pull in other modules’ documentation and build it all at once. This would mean that if we only update the modules we would have to go to the main repository to trigger a website update. We want these modules’ documentation to update as the code updates, but have a frictionless navigation experience. Or we could have a sub-domain for each module and then have five different websites.
Implementation
Five in what?
We ended up opting to build individual module sites and link them back together as seamlessly as we could. Having all the modules build their website allows us to leverage Docusaurus features like “Edit this page” to link to the corresponding repository. This also allows each module website to have its own sidebar. Because Docusaurus’ configuration is designed for a single site and not dynamic, this also means if one module site requires a specific plugin, we can have fine-grained control per site. For example, a syntax highlighting language other module sites don’t need can be separately customized, allowing flexibility on the module level.
Serving the content
Docusaurus creates Single Page Applications (SPA), which come with a challenge: how do we put the main website and the module websites together as one, yet have them update independently? Since SPA relies on rendering the `index.html` for all routes, and now we have five sets of routes when someone lands on a URL inside a module, the “404 Not Found” behaviour needs to correctly render the corresponding site’s `index.html`.
For example, we have the following paths for our module sites:
- /docs/zero
- /docs/modules/aws-eks-stack
- /docs/modules/backend-go
- /docs/modules/backend-nodejs
- /docs/modules/frontend-react
When someone lands on a URL, such as `/docs/modules/backend-go/guides/ci-cd-pipeline` from the browser, the webserver needs to identify that this file doesn’t exist, and instead of rendering the root website’s `/index.html`, it needs to render the module site’s `/index.html`, in this case, `/docs/modules/backend-go/index.html`.
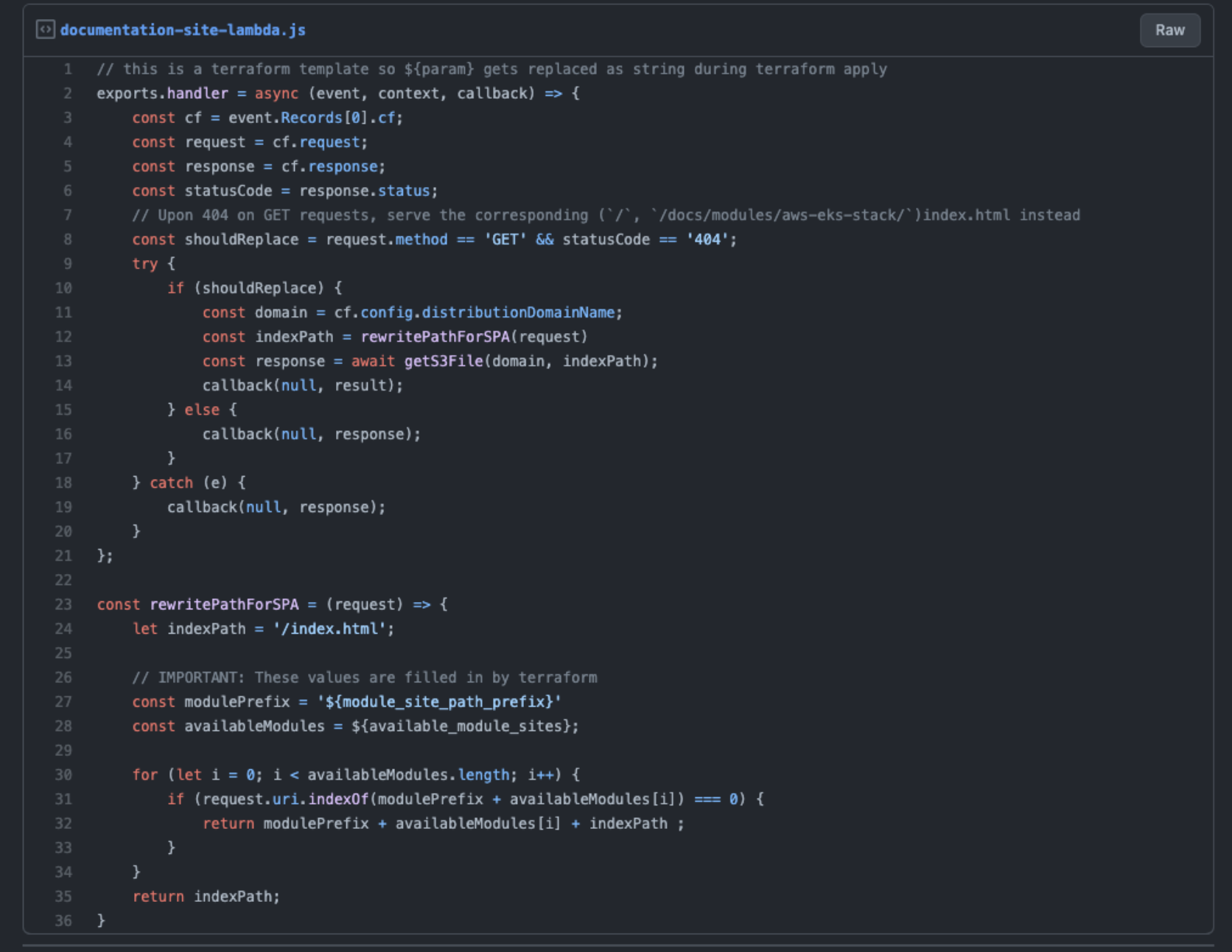
Since they are static websites, the best way to host them is with a static storage solution behind a content delivery network (CDN), in our case S3 and Cloudfront. We created a Lambda@Edge function to run during the response-origin event.

As a result, whenever a file is being fetched from the S3 bucket, we can determine the response to return and cache in CloudFront. In this case, we want to serve the backend’s `index.html`. We can rewrite the path and fetch the content from S3 directly. This might sound expensive to fetch a file during Lambda@Edge function but S3 content can also be cached, so in practice they only get fetched once until you invalidate your Cloudfront cache. Here’s an example of the code used to rewrite the response to get the correct `index.html`.

^ https://gist.github.com/davidcheung/5248e50dee5c949e68859a4487557406
Deploying the site
S3 storage

Since it’s really one site containing multiple sites worth of documentation, we are storing all the sites in one bucket, and using the same URL prefix in the bucket folder structure as the paths would be. With S3 allowing sync to start with a prefix we can pretty much treat it as a folder. S3’s sync command also allows us to specify paths to `–exclude`, `s3 path prefix` in combination with `–exclude` and `–delete` we’re able to have fine-grain control over how the website assets are pushed to the S3 buckets.

Clearing CloudFront cache
CloudFront cache invalidation is also path-driven, so we can simply invalidate a module’s cache when we’re only updating a module. For example, if we made a change to the frontend module’s documentation we can invalidate the cache for only the affected URLs.

Organizing deployment credentials — GitHub Actions
Since all the modules live under the same GitHub Organization, we can also leverage Organization-level secrets as you can configure which repositories can access them, and update them all in a single place.
Minimizing the maintenance of many module sites
Managing five different sites’ CSS and styling must be cumbersome you might think—yes it very much is. If you want to make the font colour different on one of the sites, you have to make five pull requests to five different repositories. We couldn’t completely eliminate the ugliness, but we are trying to minimize the maintenance effort. We have optimized for the most common action—updating documentation—at the expense of less common operations like those styling changes being a bit more cumbersome.
The static website bundling uses webpack, so we pushed our common elements up into an npm package. Much of the shared static styling can now be pulled down at build time instead of being committed to a repository and having to be updated every time. Using SemVer (semantic versioning) notation we can allow that package to be updated while not messing with the other dependencies’ package-lock. So if we push new changes to the common elements we can simply rerun the pipeline and the shared configurations and styling are instantly up to date!
Final thoughts
No matter what the setup is for a documentation website, content is still the most important thing and we’re constantly trying to improve our documentation. If you try out Zero and see areas of documentation where it’s lacking or outdated, please consider contributing back and submitting a pull request!